【Python】【Windows】pyenvでPythonのバージョンを管理する
MAX
MAX999blog


pythonでexcelファイルやcsvファイルなどを扱う場合、pandasが便利だが、pandasはライブラリが大きく、整形されたテーブルデータを扱う前提となっている。
pyexcelはpandasと比べるとライブラリのサイズが非常に小さい。
また、excel帳票などの整形されていないデータでも、それなりに規則性を持って読み込みやすい。
また、pyexcelでは、用途に合わせてデータ読み込み方法を選択することができる。
本記事では、結合されたセルの内容がどのように読み込まれるのかを説明する。
以下の内容のexcelファイルを読み込む。
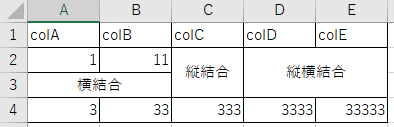
横に結合されたセル、縦に結合されたセル、縦と横に結合されたセルがあるファイルを読み込む。
なお上記のファイルは、以下のように、結合されたセルに同じ値が入っているものとして読み込まれる。
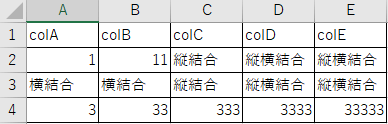
セルが結合されていることに気づかないと、同じ値に対して何度も同じ処理をしてしまうことになるので注意。
引数で指定した行を辞書のキーとして、1行ずつデータを読み込む。
1import pyexcel as pe
2
3file_name = "./data/cell_merge_sample.xlsx"
4# OrderdDictのリストとして取得
5records = pe.get_records(file_name=file_name, )
6print(f"{records}")
7# [OrderedDict([('colA', 1), ('colB', 11), ('colC', '縦結合'), ('colD', '縦横結合'), ('colE', '縦横結合')]),
8# OrderedDict([('colA', '横結合'), ('colB', '横結合'), ('colC', '縦結合'), ('colD', '縦横結合'), ('colE', '縦横結合')]),
9# OrderedDict([('colA', 3), ('colB', 33), ('colC', 333), ('colD', 3333), ('colE', 33333)])]デフォルトでは1行目の値を辞書のキーとして、2行目以降のデータが1行ごとにリストとして読み込まれる。
辞書なので、キーを指定して値を取得可能。
1for record in records:
2 print(f"{record}")
3 print(f"{record['colA']=}, {record['colB']=}")
4# OrderedDict([('colA', 1), ('colB', 11), ('colC', '縦結合'), ('colD', '縦横結合'), ('colE', '縦横結合')])
5# record['colA']=1, record['colB']=11
6# OrderedDict([('colA', '横結合'), ('colB', '横結合'), ('colC', '縦結合'), ('colD', '縦横結合'), ('colE', '縦横結合')])
7# record['colA']='横結合', record['colB']='横結合'
8# OrderedDict([('colA', 3), ('colB', 33), ('colC', 333), ('colD', 3333), ('colE', 33333)])
9# record['colA']=3, record['colB']=33なお、引数name_columns_by_rowに数値を指定することで、キーとする行を指定できる。デフォルトでは0となっており、エクセルの先頭行(1行目)となっている。
1records = pe.get_records(name_columns_by_row=1, file_name=file_name, )
2print(f"{records}")
3# [OrderedDict([('1', 'colA'), ('11', 'colB'), ('縦結合', 'colC'), ('縦横結合', 'colD'), ('縦横結合-1', 'colE')]),
4# OrderedDict([('1', '横結合'), ('11', '横結合'), ('縦結合', '縦結合'), ('縦横結合', '縦横結合'), ('縦横結合-1', '縦横結合')]),
5# OrderedDict([('1', 3), ('11', 33), ('縦結合', 333), ('縦横結合', 3333), ('縦横結合-1', 33333)])]
6
7for record in records:
8 print(record)
9# OrderedDict([('1', 'colA'), ('11', 'colB'), ('縦結合', 'colC'), ('縦横結合', 'colD'), ('縦横結合-1', 'colE')])
10# OrderedDict([('1', '横結合'), ('11', '横結合'), ('縦結合', '縦結合'), ('縦横結合', '縦横結合'), ('縦横結合-1', '縦横結合')])
11# OrderedDict([('1', 3), ('11', 33), ('縦結合', 333), ('縦横結合', 3333), ('縦横結合-1', 33333)])name_columns_by_rowに1を指定すると、エクセルの2行目(引数0が1行目に相当)をキーとして、キーの行以外の値が読み込まれる。
キーとして指定した行よりも上の行のデータも読み込まれる。
引数で指定した行を辞書のキーとして、1列ずつデータを読み込む。
1dict_data = pe.get_dict(file_name=file_name)
2pprint(dict_data)
3# OrderedDict([('colA', [1, '横結合', 3]),
4# ('colB', [11, '横結合', 33]),
5# ('colC', ['縦結合', '縦結合', 333]),
6# ('colD', ['縦横結合', '縦横結合', 3333]),
7# ('colE', ['縦横結合', '縦横結合', 33333])])なお、引数name_columns_by_rowを指定することで、指定した行の値をキーとすることができる。(デフォルトでは0)
1dict_data = pe.get_dict(file_name=file_name, name_columns_by_row=1)
2pprint(dict_data)
3# OrderedDict([('1', ['colA', '横結合', 3]),
4# ('11', ['colB', '横結合', 33]),
5# ('縦結合', ['colC', '縦結合', 333]),
6# ('縦横結合', ['colD', '縦横結合', 3333]),
7# ('縦横結合-1', ['colE', '縦横結合', 33333])])辞書形式での読み込みは、キーとする行がある場合に便利。
2次元のリスト形式での読み込みは、エクセルのデータ構造をそのまま表しているので、シンプルで分かりやすいかもしれない。
1import pyexcel as pe
2from pprint import pprint
3
4array_data = pe.get_array(file_name=file_name)
5pprint(array_data)
6# [['colA', 'colB', 'colC', 'colD', 'colE'],
7# [1, 11, '縦結合', '縦横結合', '縦横結合'],
8# ['横結合', '横結合', '縦結合', '縦横結合', '縦横結合'],
9# [3, 33, 333, 3333, 33333]]引数start_rowの値を指定することで、指定した行以降のデータを読み込むことができる。
デフォルトではstart_rowは0となっている。
1array_data = pe.get_array(file_name=file_name, start_row=1)
2pprint(array_data)
3# [[1, 11, '縦結合', '縦横結合', '縦横結合'],
4# ['横結合', '横結合', '縦結合', '縦横結合', '縦横結合'],
5# [3, 33, 333, 3333, 33333]]2次元リストで読み込む場合、整形されていないデータを読み込むのに便利かもしれない。

