【Python】【Seaborn】日本語文字化けを直す
MAX
MAX999blog


seabornのhistplotを使うと簡単にヒストグラムを作成できる。
hueを指定する場合、他にもオプションを指定することで色々な形式のヒストグラムを作成できる。
重ね合わせ、隣り合わせ、積み上げなどを指定できる。
seabornで取得できるtipsのデータを使う。
1import seaborn as sns
2
3df_tips = sns.load_dataset("tips")
4print(df_tips)
5# total_bill tip sex smoker day time size
6# 0 16.99 1.01 Female No Sun Dinner 2
7# 1 10.34 1.66 Male No Sun Dinner 3
8# 2 21.01 3.50 Male No Sun Dinner 3
9# 3 23.68 3.31 Male No Sun Dinner 2
10# 4 24.59 3.61 Female No Sun Dinner 4
11# .. ... ... ... ... ... ... ...ベースとなるグラフ表示のコードは以下の通り。
1# グラフサイズと背景色の設定
2plt.figure(figsize=(8, 4.5), facecolor="w")
3# ヒストグラム作成
4sns.histplot(data=df_tips, x="total_bill", stat="count",
5 hue="time", multiple="layer")
6# グラフタイトルの設定
7title = "count_layer"
8plt.title(title)
9# グラフ表示
10plt.tight_layout()
11plt.show()
hueに指定しているtime列はLunchとDinnerの2種類の値があるため、それぞれのヒストグラムが描画される。
その際、sns.histplotの引数のmultipleを色々変えていくことで、グラフを重ねたり、積み上げたりできる。
histplot()のmultipleにlayerを設定すると、ヒストグラムが重なって表示される。
デフォルトはmultiple=”layer”になっている。
1# multipleにlayerを指定する。
2sns.histplot(data=df_tips, x="total_bill", stat="count",
3 hue="time", multiple="layer")
4
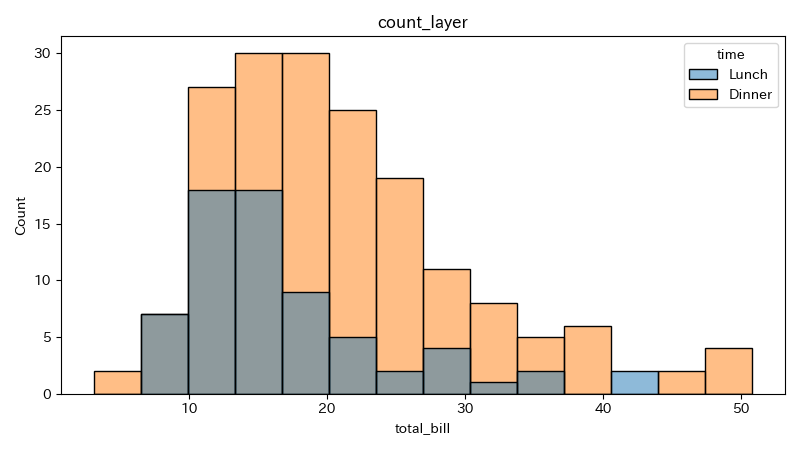
multipleがlayerの場合、alpha(グラフの透明度を指定する引数)はデフォルトでは0.5になる。
グラフの緑っぽくなっている部分はLunchとDinnerが重なっている部分である。
ヒストグラムの重なり具合によるが、3色以上の表示にはあまり向かない。
multipleにdodgeを指定すると、ビン毎に各カテゴリーのグラフを隣に並べて表示できる。
1# multipleにdodgeを指定する。
2sns.histplot(data=df_tips, x="total_bill", stat="count",
3 hue="time", multiple="dodge", alpha=0.5)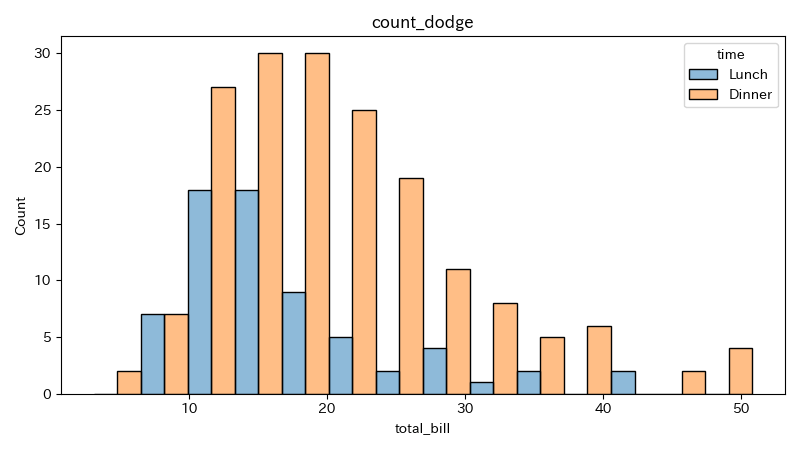
隣り合わせなので、3色以上になっても重なりすぎて度数が分からなくなることはない。
しかし、カテゴリーの種類が増えるとグラフが見にくくなるため、適度な数にしておいた方が良い。
multipleにstackを指定すると、ヒストグラムを積み上げて表示できる。
1# multipleにstackを指定する。
2sns.histplot(data=df_tips, x="total_bill", stat="count",
3 hue="time", multiple="stack", alpha=0.5)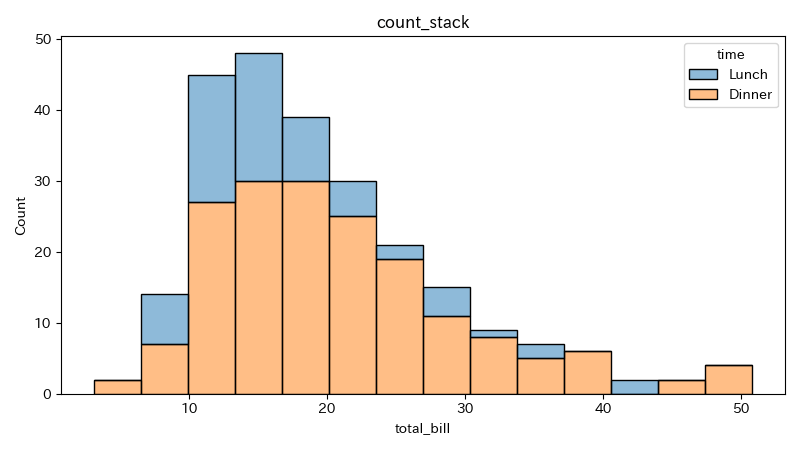
色を分けずに1色に塗った場合のグラフはhueを指定しない場合と同じ形になる。
度数が積みあがっているため、カテゴリー毎の分布は少し見にくくなる。
全体の分布を確認しつつ、各ビンのカテゴリー毎の割合を確認したい時などに使う。
multipleにfillを指定すると、各ビンでの各カテゴリーの割合を面積で表示できる。
1# multipleにfillを指定する。
2sns.histplot(data=df_tips, x="total_bill", stat="count",
3 hue="time", multiple="fill", alpha=0.5)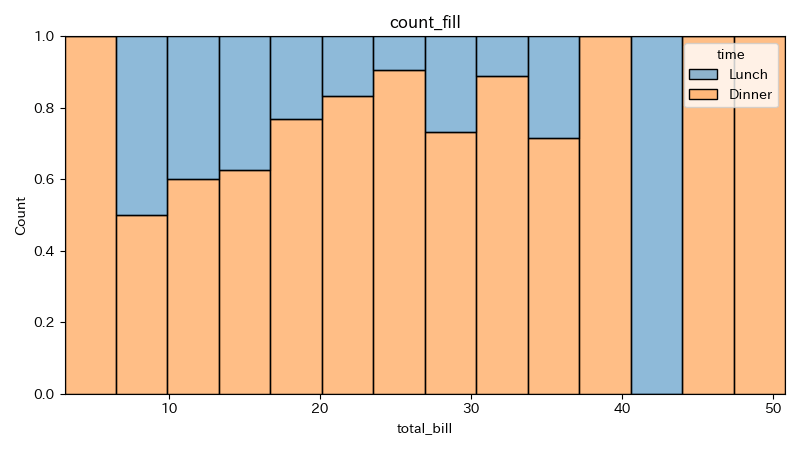
y軸は0~1の割合となっている。
度数ではなく、各ビンにおけるカテゴリーの割合を見たい場合に使う。
statにdensityを指定することで、y軸を度数ではなく確率密度で表示できる。
1# statにdensityを指定する
2sns.histplot(data=df_tips, x="total_bill", stat="density",
3 hue="time", multiple="dodge", alpha=0.5)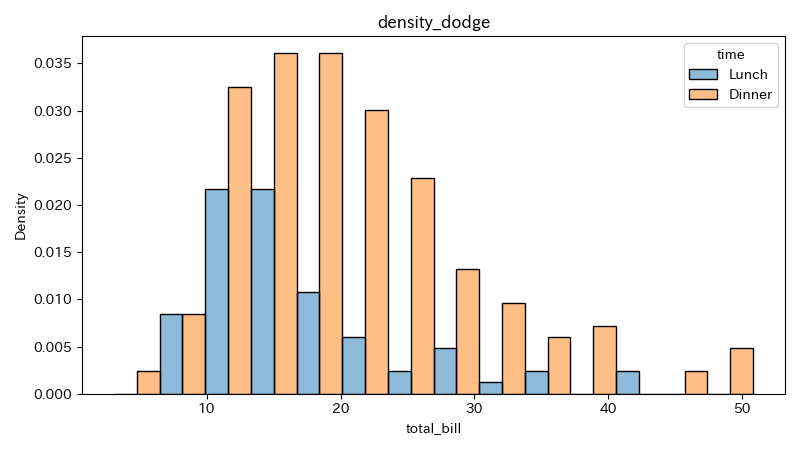
1# データ読み込み
2df_tips = sns.load_dataset("tips")
3
4# 同じビンを重ねて表示
5sns.histplot(data=df_tips, x="total_bill", stat="count",
6 hue="time", multiple="layer")
7
8# ビンを隣り合わせて表示
9sns.histplot(data=df_tips, x="total_bill", stat="count",
10 hue="time", multiple="dodge", alpha=0.5)
11
12# ビンを積み上げて表示
13sns.histplot(data=df_tips, x="total_bill", stat="count",
14 hue="time", multiple="stack", alpha=0.5)
15
16# ビンを面積の割合で表示
17sns.histplot(data=df_tips, x="total_bill", stat="count",
18 hue="time", multiple="fill", alpha=0.5)
19
20# 確率密度で表示
21sns.histplot(data=df_tips, x="total_bill", stat="density",
22 hue="time", multiple="dodge", alpha=0.5)
